*redis面试题
Redis 常见面试问题总结和答案,涵盖 Redis 核心概念、数据类型、持久化、高可用、性能优化及 Redis 7.x 新特性。
*什么是Redis?
Redis(Remote Dictionary Server)是一个开源的 Key-Value 内存数据库,由 ANSI C 编写,遵守 BSD 协议。
数据存储在内存中,读写速度极快,典型场景每秒可处理超过 10 万次读写操作。广泛应用于缓存、分布式锁、消息队列、计数器、排行榜、实时系统等场景,并支持事务、持久化、Lua 脚本、LRU/LFU、发布订阅、Stream 流及多种集群方案。
- GitHub 源码:https://github.com/redis/redis
- Redis 官网:https://redis.io/
*Redis 支持哪些数据类型?
Redis 键的类型只能为字符串,值支持多种数据类型:
*String(字符串)
- 格式:
SET key value - 二进制安全,可以包含任何数据(如图片、序列化对象)。
- 最基本的数据类型,一个键最大能存储 512MB。
- 常用命令:SET、GET、SETNX、INCR、DECR、MSET、MGET、APPEND、STRLEN
*Hash(哈希)
*List(列表)
- 简单的字符串列表,按插入顺序排序。
- 支持从头部(LPUSH)或尾部(RPUSH)插入。
- 可用作队列(LPUSH + BRPOP)或栈(LPUSH + LPOP)。
- 常用命令:LPUSH、RPUSH、LPOP、RPOP、LRANGE、LLEN、LREM、LINDEX
*Set(集合)
- 无序且唯一的字符串集合。
- 基于哈希表实现,添加、删除、查找复杂度均为 O(1)。
- 支持交集、并集、差集运算。
- 常用命令:SADD、SREM、SMEMBERS、SISMEMBER、SINTER、SUNION、SDIFF
*Sorted Set(有序集合)
- 每个元素关联一个 double 类型的分数,按分数从小到大排序。
- 成员唯一,但分数可重复。
- 非常适合排行榜、延时队列等场景。
- 常用命令:ZADD、ZREM、ZRANGE、ZREVRANGE、ZREVRANK、ZRANGEBYSCORE
*Stream(流)
- Redis 5.0 引入的日志型数据结构,类似 Kafka 的日志概念。详见 Redis Stream 教程。
- 支持消费者组(Consumer Group)和消息确认机制(ACK)。
- 适合实现可靠的消息队列。
- 常用命令:XADD、XREAD、XREADGROUP、XRANGE、XACK、XDEL
*Bitmap(位图)
*HyperLogLog
*Geo(地理空间)
- 存储地理位置坐标(经纬度),支持半径查询。
- 基于 Sorted Set 实现。
- 常用命令:GEOADD、GEOPOS、GEODIST、GEORADIUS、GEORADIUSBYMEMBER
- ⚠️ Redis 6.2.0+ 已弃用 GEORADIUS / GEORADIUSBYMEMBER,推荐使用 GEOSEARCH。
*什么是 Redis 持久化?有哪些方式?优缺点是什么?
持久化是将内存中的数据写入磁盘,防止服务器宕机导致数据丢失。Redis 提供两种持久化方式:
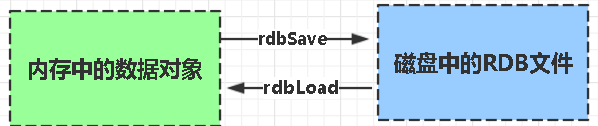
*RDB(Redis DataBase)
- 在指定时间间隔内,将内存中的数据集快照写入磁盘。
- 触发方式:手动 SAVE/BGSAVE,或配置自动触发(如
save 900 1)。 - 优点:
- 文件紧凑,适合备份和灾难恢复。
- 恢复速度快,加载 RDB 文件直接还原数据。
- 对性能影响较小(子进程执行写入)。
- 缺点:
- 最后一次快照后的数据可能丢失(数据完整性较差)。
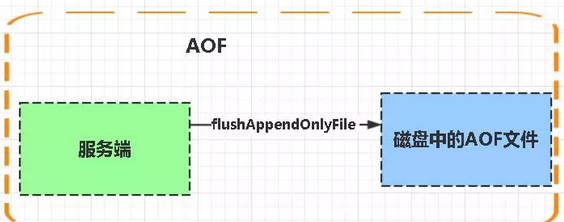
*AOF(Append Only File)
- 记录每个写操作命令,以 Redis 协议格式追加到文件。详见 Redis 持久化机制。
- 支持三种同步策略:
always(每次写入都同步)、everysec(每秒同步,默认)、no(由操作系统决定)。 - 优点:
- 数据完整性更高,最多丢失 1 秒数据(默认策略)。
- AOF 文件可人工审查和修改。
- 缺点:
- 文件通常比 RDB 大。
- 恢复速度比 RDB 慢。
- 高并发写入时性能开销更大。
*混合持久化(Redis 4.0+)
- AOF 重写时,先将当前数据以 RDB 格式写入 AOF 文件开头,后续增量操作以 AOF 格式追加。
- 兼顾 RDB 的快速恢复和 AOF 的数据完整性。
*RDB vs AOF 如何选择?
- 对数据完整性要求高,优先使用 AOF。
- 对恢复速度要求高,优先使用 RDB。
- 可同时开启 RDB 和 AOF,Redis 7.x 默认推荐两者都开启,恢复时优先使用 AOF。
*RESP 协议是什么?有什么特点?
RESP(REdis Serialization Protocol)是 Redis 客户端与服务端之间的通信协议。
特点:
- 实现简单、解析快速、可读性好。
- 支持多种数据类型标识:
+简单字符串(Simple Strings)-错误(Errors):整数(Integers)$批量字符串(Bulk Strings)*数组(Arrays)
*Redis 有哪些架构模式?各自特点是什么?
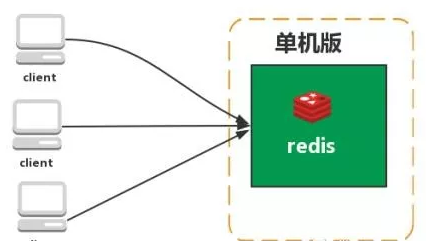
*1. 单机模式
- 特点:部署简单,适合数据量小、并发量低的场景。
- 问题:单点故障、内存和处理能力受限、无法高可用。
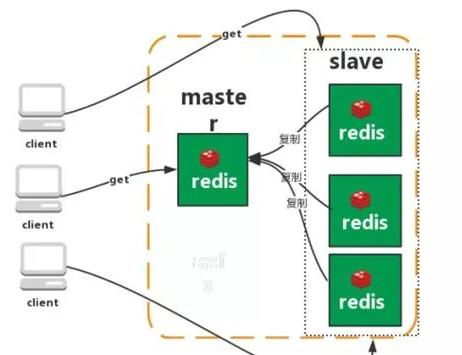
*2. 主从复制(Replication)
- 一个主节点(Master)负责写操作,多个从节点(Slave)负责读操作。
- 主从数据实时同步,降低主节点读压力。
- 问题:无法自动故障转移,主节点写压力未分散,主节点宕机需手动切换。
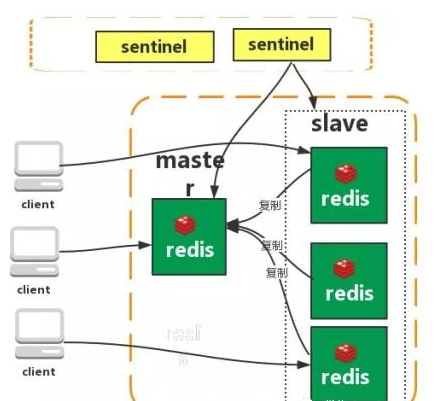
*3. 哨兵模式(Sentinel)
- 监控主从节点状态,主节点宕机时自动完成故障转移(选举新主节点)。
- 特点:高可用、自动监控、自动故障迁移。
- 缺点:主从切换需要时间(秒级),期间可能丢数据;未解决写压力瓶颈。
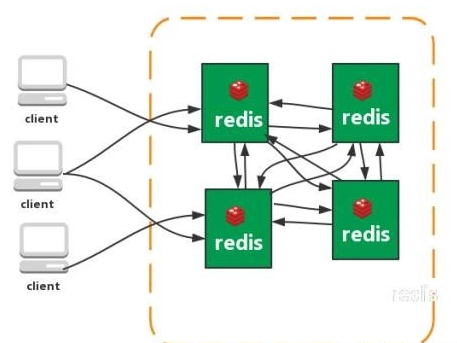
*4. 集群模式(Cluster)
- Redis 3.0+ 官方集群方案,采用无中心架构。
- 数据按 16384 个哈希槽(Slot)分布在多个节点,每个节点保存部分数据和整个集群状态。
- 节点间通过 Gossip 协议通信,实现故障自动转移。
- 特点:
- 无中心架构,可线性扩展至 1000 个节点。
- 数据分片存储,支持动态扩缩容。
- 高可用,部分节点宕机集群仍可服务。
- 客户端通过 MOVED/ASK 重定向访问正确节点。
- 缺点:
- 资源隔离性较差,多租户场景易相互影响。
- 数据异步复制,不保证强一致性。
*什么是一致性哈希?什么是哈希槽?
*一致性哈希(Consistent Hashing)
- 常用于客户端分片或代理分片(如 Twemproxy)。
- 将节点和数据都映射到一个哈希环上,数据顺时针找到最近的节点存储。
- 增删节点时只影响相邻节点,大幅减少数据迁移量。
- 引入虚拟节点解决数据倾斜问题。
*哈希槽(Hash Slot)
- Redis Cluster 采用 16384(214)个哈希槽进行数据分片。
- 键通过
CRC16(key) % 16384计算所属槽。 - 每个主节点负责一部分槽,槽可动态迁移实现扩缩容。
- 相比一致性哈希,哈希槽更易于管理和重新分配。
*Redis 常用命令有哪些?
*键操作
KEYS pattern:查找所有符合模式的键(生产环境慎用,性能开销大)。SCAN cursor [MATCH pattern] [COUNT count]:渐进式遍历键(推荐替代 KEYS)。EXISTS key:判断键是否存在。DEL key:删除键。EXPIRE key seconds:设置键的过期时间。TTL key:查看剩余生存时间。PERSIST key:移除过期时间。RENAME key newkey:重命名键。TYPE key:返回键的数据类型。SELECT index:切换数据库(0-15)。MOVE key db:将键移动到指定数据库。
*字符串操作
SET key value [NX|XX] [EX seconds|PX milliseconds]:设置键值。GET key:获取值。SETNX key value:仅在键不存在时设置(常用于分布式锁)。INCR key/DECR key:原子增减。INCRBY key increment/DECRBY key decrement:按指定值增减。MGET key1 key2 .../MSET key1 value1 key2 value2 ...:批量操作。APPEND key value:追加字符串。STRLEN key:获取字符串长度。GETSET key value:设置新值并返回旧值。
*使用过 Redis 分布式锁吗?它是怎么实现的?
*基本实现
使用 SET key value NX EX seconds 命令:
NX:仅在键不存在时设置(保证互斥)。EX:设置过期时间(防止死锁)。
SET resource_lock my_random_value NX EX 30
释放锁时,使用 Lua 脚本确保原子性判断和删除:
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
*RedLock 算法
- Redis 官方提出的分布式锁算法,需在多个独立 Redis 实例上获取锁。
- 多数实例(N/2+1)获取成功且总耗时小于锁有效期,则认为加锁成功。
- 争议:Martin Kleppmann 指出 RedLock 依赖时钟同步,存在安全性问题。实际场景中,使用 ZooKeeper 或 etcd 实现分布式锁通常更可靠。
*使用过 Redis 做异步队列吗?
*List 实现简单队列
*Pub/Sub 实现广播
- 发布者
PUBLISH channel message,订阅者SUBSCRIBE channel。 - 实现 1:N 消息广播,但消息不持久化,消费者离线期间消息丢失。
*Stream 实现可靠队列(推荐)
- XADD 添加消息,XREADGROUP 消费者组消费。
- 支持消息确认(XACK)和待处理列表(PEL),消息不丢失。
- 适合需要高可靠性的消息队列场景。
*缓存穿透、缓存击穿、缓存雪崩是什么?如何避免?
*缓存穿透(Cache Penetration)
- 定义:查询一个数据库和缓存中都不存在的数据,导致请求直达数据库。
- 危害:恶意攻击可利用此漏洞压垮数据库。
- 解决:
- 布隆过滤器(Bloom Filter)预先拦截不存在的数据。
- 缓存空对象(设置较短过期时间)。
- 接口层增加参数校验和限流。
*缓存击穿(Cache Breakdown)
- 定义:某个热点 key 突然过期,大量请求同时打到数据库。
- 解决:
- 热点 key 永不过期,或异步更新缓存。
- 加互斥锁,只允许一个线程重建缓存(SETNX 实现)。
*缓存雪崩(Cache Avalanche)
- 定义:大量缓存同时过期或 Redis 宕机,导致数据库压力激增。
- 解决:
- 过期时间加随机值,分散失效时间点。
- 多级缓存(本地缓存 + Redis + 数据库)。
- 高可用架构(Redis 集群 + 哨兵)。
- 熔断降级,数据库压力过大时拒绝部分请求。
*Redis 的内存淘汰策略有哪些?
当内存达到 maxmemory 限制时,Redis 提供以下淘汰策略:
| 策略 | 说明 |
|---|---|
noeviction |
默认策略,不淘汰数据,新写入直接报错。 |
allkeys-lru |
在所有键中淘汰最近最少使用(LRU)的键。 |
allkeys-lfu |
在所有键中淘汰使用频率最低(LFU)的键。 |
allkeys-random |
在所有键中随机淘汰。 |
volatile-lru |
在设置了过期时间的键中淘汰最近最少使用的。 |
volatile-lfu |
在设置了过期时间的键中淘汰使用频率最低的。 |
volatile-random |
在设置了过期时间的键中随机淘汰。 |
volatile-ttl |
在设置了过期时间的键中淘汰即将过期的。 |
建议:
- 纯缓存场景使用
allkeys-lru或allkeys-lfu。 - Redis 4.0+ 推荐使用 LFU(更精准反映真实访问热度)。
*Redis 大 Key 和热 Key 问题如何处理?
*大 Key(Big Key)
- 定义:单个 key 对应的 value 过大(如 String 超过 10KB,集合元素超过 5000 个)。
- 危害:
- 阻塞其他命令(Redis 单线程)。
- 序列化/反序列化开销大。
- 网卡带宽占用高。
- 主从同步延迟。
- 发现:
redis-cli --bigkeys或MEMORY USAGE key。 - 解决:
- 拆分为多个小 key(如 Hash 分桶)。
- 删除时使用 UNLINK(异步删除,非阻塞)。
- 避免使用
KEYS *遍历大集合。
*热 Key(Hot Key)
- 定义:单个 key 被超高并发访问(如秒杀商品的库存 key)。
- 危害:单节点 CPU 和网络瓶颈。
- 解决:
- 本地缓存(二级缓存)降低 Redis 访问压力。
- 热 Key 拆分(如
stock:item:1拆分为stock:item:1:0、stock:item:1:1多个副本,读写时随机选择)。 - 读写分离,增加从节点分散读压力。
*Redis 脑裂问题是什么?如何解决?
*脑裂(Split-Brain)
- 当主节点网络分区(与从节点和哨兵断开连接,但与客户端仍连通)时:
- 哨兵认为主节点宕机,选举新主节点。
- 旧主节点仍在接受客户端写入,导致数据不一致。
- 网络恢复后,旧主节点变为从节点,其分区期间的数据被清空。
*解决
Redis 提供 min-slaves-to-write 和 min-slaves-max-lag 配置:
min-slaves-to-write 1:至少 1 个从节点连接时才允许写入。min-slaves-max-lag 10:从节点延迟不超过 10 秒。
当主节点与多数从节点断开时,拒绝写入,避免数据丢失。
*Redis 事务是什么?有哪些特性?
Redis 通过 MULTI、EXEC、DISCARD、WATCH 实现事务:
MULTI
INCR foo
INCR bar
EXEC
*事务特性
- 原子性:Redis 事务中的命令会按顺序执行,不会被其他客户端命令中断。但不支持回滚——如果某条命令语法错误,其他命令仍会执行。
- 一致性:事务执行前后数据保持一致。
- 隔离性:事务执行期间,其他客户端请求不会插入到事务命令之间(单线程模型保证)。
- 持久性:依赖持久化配置(RDB/AOF)。
*WATCH 乐观锁
WATCH key监控键,如果在 EXEC 之前键被其他客户端修改,事务将放弃执行(返回nil)。- 实现 CAS(Compare And Swap)语义。
*与关系型数据库事务的区别
- Redis 事务不支持回滚(Rollback),出错后不能撤销已执行的命令。
- 更适合作为批量操作的打包工具,而非复杂事务场景。
*什么是 Redis Pipeline?
Pipeline 允许客户端一次性发送多个命令,Redis 执行后一次性返回结果,减少网络往返时间(RTT)。
- 优点:显著提升批量操作的吞吐量(可达 10 倍以上)。
- 注意:Pipeline 不是原子操作,命令之间可能被其他客户端插入。如果需要原子性,应使用 Lua 脚本或事务。
*Redis 的 Lua 脚本有什么作用?
Redis 支持执行 Lua 脚本(EVAL / EVALSHA):
- 原子性:整个 Lua 脚本在 Redis 中单线程原子执行,不会被其他命令中断。
- 减少网络开销:将多个操作封装到一个脚本中,只需一次网络往返。
- 复杂逻辑:可实现条件判断、循环等逻辑(如分布式锁的释放判断)。
注意:
- Lua 脚本执行时间不应过长,否则会阻塞 Redis(影响其他命令)。
- Redis 7.0+ 引入 Redis Functions,允许将 Lua 函数持久化到服务器,比临时脚本更高效。
*Redis 7.0 新特性有哪些?
Redis 7.0 带来多项重要更新:
*1. Redis Functions
- 将 Lua 函数作为持久化模块加载到 Redis,函数在重启后仍然可用。
- 相比临时 Lua 脚本,Functions 可复用、可管理,执行效率更高。
*2. ACL 改进
- 更细粒度的权限控制,支持按命令、键模式、频道限制用户权限。
- ACL LOG 记录权限拒绝事件,便于安全审计。
*3. Sharded Pub/Sub
- 集群模式下,发布订阅按槽分片,避免全集群广播。
- 大幅提升集群模式下的 Pub/Sub 性能和可扩展性。
*4. 多部分 AOF(MP-AOF)
- AOF 文件拆分为多个部分(基础 RDB + 增量 AOF),重写更轻量。
- 减少磁盘 I/O 和内存开销,提升持久化性能。
*5. 其他改进
- 命令子命令级别的权限控制。
- 集群支持主机名(不再仅支持 IP)。
- 客户端追踪改进(客户端缓存更高效)。
- 新增多个命令和参数优化。
*适用版本
本文内容基于 Redis 6.0+ / 7.x,部分特性(如 Functions、MP-AOF、Sharded Pub/Sub)需要 Redis 7.0+。命令示例在 Redis 6.2+ 环境测试通过,未特别标注版本的功能适用于主流稳定版本。
*Redis 的用途总结
| 场景 | 实现方式 |
|---|---|
| 缓存 | String / Hash 存储热点数据,设置过期时间 |
| 计数器 | INCR / DECR 原子操作 |
| 分布式锁 | SETNX + EX + Lua 释放 |
| 会话缓存 | Hash 存储用户 Session,设置过期时间 |
| 排行榜 | Sorted Set(ZADD、ZREVRANGE) |
| 消息队列 | List(LPUSH + BRPOP)或 Stream |
| 延时队列 | Sorted Set(score 为执行时间戳) |
| 布隆过滤器 | RedisBloom 模块或 Bitmap 模拟 |
| 地理位置 | Geo(GEOADD、GEORADIUS) |
| 统计UV/PV | HyperLogLog(PFADD、PFCOUNT) |
| 实时系统 | Pub/Sub 或 Stream 推送消息 |
| 查找表 | String / Hash 存储 DNS、配置等 |
*Redis 常见问题速查
*Redis 是单线程的,为什么还这么快?
- 纯内存操作:数据在内存中,读写无需磁盘 I/O。
- 单线程模型:避免多线程上下文切换和锁竞争。
- 高效数据结构:String、Hash、Skip List 等都经过极致优化。
- I/O 多路复用:基于 epoll/kqueue 的事件驱动模型,单线程可同时处理数万连接。
- RESP 协议简单:解析开销极低。
*单线程如何充分利用多核 CPU?
- 单实例无法利用多核,但可在单机上部署多个 Redis 实例,或使用 Redis Cluster。
- 对于需要大量计算的场景(如复杂 Lua 脚本),可开启 Redis 7.0+ 的 Function 功能或拆分逻辑到应用层。
*Redis 如何处理并发竞争?
- 单线程串行执行天然避免并发竞争。
- 对于需要判断后修改的场景,使用 WATCH + 事务,或 Lua 脚本保证原子性。